fredag 4 januari 2019
Sagan om Sverige - Från fem till tio miljoner
Det här är ett litet experiment med en ny presentationsform. Jag har faktiskt vågat mig på att göra en helt animerad visualisering i form av en film. Som statistiskt historieberättande finns det en hel del poänger med det sättet att presentera. Nackdelen är att det tar avsevärd tid att skapa varje visualisering. Vi får se hur det faller ut. Om det funkar, så är tanken att det ska bli fler delar i serien, med lite olika teman, men fokus på hur utvecklingen i Sverige sett ut under de senaste dryga hundra åren. Först ut är i alla fall befolkningsutvecklingen. Håll till godo!
torsdag 11 oktober 2018
Grundläggande visualiseringsteori, del 3: Cirkeldiagrammet - älskat och hatat
En av de saker som kanske mest förvånar en vanlig användare när man kommer mer i kontakt med visualiseringsvärlden, är det kompakta motståndet mot cirkeldiagram. Cirkeldiagrammet (eller, om man så vill, tårtdiagram alternativt pajdiagram) är ju en vanlig form av framställning, som dyker upp dagligen i tidningar, på nätet, i rapporter - överallt där siffror ska redovisas. Vad kan vara så fel med det?

Att cirkeldiagrammet avskys av så många som jobbar professionellt med visualisering (Stephen Few: Save the pies for dessert, Cole Nussbaumer: Death to pie charts, Edward Tufte: The only thing worse than a pie chart is several of them) är inte en fråga om tycke och smak, utan helt och hållet baserat på hur effektivt det är på att förmedla data.
Huvudpoängen är följande: visual cue i ett cirkeldiagram är vinkeln på tårtbitarna och storleken på deras ytor. Går vi tillbaka till det mest basala i visualiseringsdiagram, Cleveland & McGill's visuella hierarki, hamnar såväl vinkel som yta långt ner i listan. De är helt enkelt dåliga metoder att förmedla data. I princip är andra former av diagram alltid bättre än cirkeldiagram.
Men, invänder vän av ordning, cirkeldiagram är ju perfekta för att visa andelar. Man ser tydligt hur stor del av helheten varje sektion representerar. Ja och nej (mest nej). Vi tar ett exempel för att illustrera. Här är ett exempel på ett vanligt cirkeldiagram, med sex olika kategorier. Kategori C kan lätt utläsas till 25 procent, en fjärdedel av diagrammets yta.

Det här är cirkeldiagrammets egentliga styrka; att visa en andel av helheten. 25 procent av 100 procent framstår tydligt. Men om vi bara stuvar om kategorierna lite, till att exempelvis sortera dem efter storlek?

Plötsligt är det inte så självklart att kategori C är exakt 25 procent längre. När start- och slutpositionerna var lodräta eller vågräta kunde ögat enkelt uppfatta andelen. Nu är vinkeln fortfarande 90 grader, men det är nästan omöjligt att exakt bedöma storleken på tårtbiten.
Vad gör man då istället? En vanlig lösning är att ange de exakta andelarna som etiketter, kanske till och med kategorinamnen som etiketter.

Men vad har vi fått nu? Vad är visual cue? Det är inte längre vinkeln på tårtbiten eller ytan, utan bara det angivna siffervärdet på etiketten. Och då kan vi lika gärna ha en vanlig tabell. Eller, för den delen, ett stapeldiagram, som är den form som bäst förmedlar kategoridata.

Är cirkeldiagram då alltid fel? Nej, inte helt och hållet. Forskningen visar att det finns en specifik tillämpning där de är det bättre alternativet. I artikeln “Displaying Proportions and Percentages” visar Ian Spence och Stephan Lewandwsky - något förenklat - att cirkeldiagram kan fungera bra när summan av två kategorier ska jämföras med summan av två andra kategorier, som i detta exempel:

Vad är störst - A+B eller C+D? I just det här fallet visar det sig att cirkeldiagram faktiskt är bättre än staplar. Nu är det här ett ganska smalt tillämpningsområde, och möjligen kan det finnas fler exempel som ännu inte har beforskats. Men på det stora hela är pajdiagram alltid sämre än andra alternativ.
Jag gillar pajer. Här är en som jag och min dotter bakade här om dagen. Men spara pajerna till fika. Håll dem borta från siffertrillandet om du inte vet exakt vad du håller på med!

torsdag 6 september 2018
Partier i himmel och helvete
GAL-TAN-skalan är sååå 2017. Inspirerad av en egen förflugen Facebook-kommentar kring islamistskandaler i Miljöpartiet, insåg jag att partiernas kategorisering måste moderniseras. Istället är det ju religionen som är den stora vågdelaren! Det räcker inte längre att hålla rent åt höger för de borgerliga och åt vänster för socialisterna. Nej, nu får man hålla rent uppåt himlen. Och kanske nedåt också. Vi vill ju inte att några fundamentalistiska ateister börjar infiltrera partierna.
Vilka ligger i riskzonen då? Det visade sig inte vara helt lätt att hitta data över de olika partiernas religiositet. Men efter lite letande snubblade jag över en Sifo-undersökning beställd av tidningen Dagen, med partiopinion för kristna väljare. En liknande undersökning av muslimska väljares partisympatier hittade jag hos statsvetaren Magnus Hagevi. Tillsammans står dessa två grupper för de flesta religiösa i landet.
Genom att räkna om de religiösas partisympatier till en kvot av de totala sympatierna (och vikta ihop kristna och muslimer efter deras andel av befolkningen) och sedan normalisera kvoten till en tiogradig skala, får vi fram hur över- eller underrepresenterade varje parti är hos de religiösa i befolkningen. Är de närmare himlen eller helvetet? Höger-vänsterskalan är etablerad sen tidigare.
Partiers placering enligt Höger-Vänster-Himmel-Helvetesskalan

Några av resultaten blev förväntade, andra mer oväntade. Att Kristdemokraterna har närmare till det gudomliga kunde nog de flesta räkna ut på förhand. Däremot kanske det inte var helt uppenbart att Vänsterpartiet och Liberalerna har nästan lika nära till skärselden båda två. Och att Centern flåsar KD så pass nära i nacken på jakten efter frälsning kanske inte heller var självklart för alla.
Socialdemokraterna är ett intressant särfall. Kristna väljare tenderar att föredra dem i lite mindre utsträckning än hela väljarkollektivet, men de muslimska väljarna stödjer dem i nästan ofattbart stor utsträckning (61 procent). Detta tippar upp partiets placering bland religiösa väljare till samma genomsnittliga nivå som hos samtliga väljare.
Så, här har vi indelningen av partier vi har att förhålla oss till i fortsättningen. Bara att vänja sig. Och nu blir det ingen mer valstatistik före valet. Jag lovar.
tisdag 4 september 2018
Spurtar och spaghetti
Valen närmar sig med stormsteg, men vi hinner med en sista djupdykning i röststatistiken. Nu lämnar vi SCB:s Partisympatiundersökning och tittar istället lite närmare på valrörelsens slutspurt. Mycket kan hända de sista månaderna eller till och med veckorna - men hur visualiserar man det på bästa sätt?
För att få ett datamaterial med så täta observationer som möjligt den sista tiden fram till valet, hämtar jag nu siffror från Pollofpolls.se, en sammanvägning av de flesta större opinionsinstituts mätningar. Det jag är intresserad av den här gången är hur de olika partierna klarar av den sista perioden före ett val, historiskt sett. Finns det några trender, skillnader, likheter, intressanta iakttagelser? För enkelhetens skull - och för att jämförbara data är någorlunda lättillgängliga - avgränsar jag mig till valen 2010, 2014 och 2018, och tittar på opinionsutvecklingen för varje parti från årsskiftet fram till valet respektive valår.
Och då blir ju frågan - hur visar man detta grafiskt på bästa sätt? Det handlar om tidsseriedata, därmed blir standardvalet ett linjediagram. Inga konstigheter. Åtta partier, tre valår. In med alltsammans i ett linjediagram med de etablerade partifärgerna för att särskilja utvecklingen.
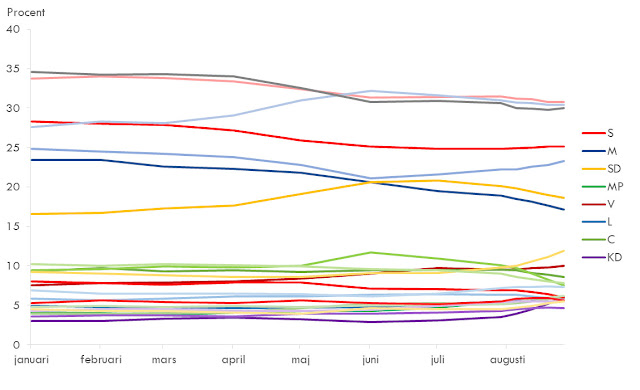
Aj, mina ögon! Det här blev inte vackert. Den som kan dra några vettiga slutsatser av det här vinner en årsprenumeration på Qvintensen. Vad vi har landat i här, är vad som ibland brukar benämnas Spaghettidiagram. Det är helt enkelt linjediagram med ett flertal linjer som korsar varandra i sån utsträckning att det inte går att göra någon egentlig analys. Tyvärr är det här vanligare än vad man kan tro. Det är också en av linjediagrammens svagheter; det är alldeles för lätt att dränka dem i närliggande datapunkter så att man inte ser skogen för alla träd.



Men det här blev ju inte så roligt. Det här är samma typ av diagram man ser nästan dagligen under valspurtens sista skälvande dagar. Varje partis utveckling jämfört med de andra partierna. Det blir ganska svårt att dra några generella slutsatser om hur varje parti historiskt har klarat valspurterna, och vilka likheterna eller skillnaderna är mellan åren. Nej, att dra isär diagrammen efter år blev inte så bra.
Då testar vi att titta på ett parti i taget istället, med utvecklingen under respektive valår. Genast blir det mycket mer intressant.




Nu är det direkt flera slutsatser man kan dra. Genom att fokusera jämförelser på hur respektive parti utvecklas under valåren i avskilda diagram, slipper vi spaghettiproblematiken. Oftare än man tror är det faktiskt bättre att dela upp data i flera parallella diagram. Det finns inget egenvärde att klämma in allting i ett enda superdiagram bara för sakens skull.
För att få ett datamaterial med så täta observationer som möjligt den sista tiden fram till valet, hämtar jag nu siffror från Pollofpolls.se, en sammanvägning av de flesta större opinionsinstituts mätningar. Det jag är intresserad av den här gången är hur de olika partierna klarar av den sista perioden före ett val, historiskt sett. Finns det några trender, skillnader, likheter, intressanta iakttagelser? För enkelhetens skull - och för att jämförbara data är någorlunda lättillgängliga - avgränsar jag mig till valen 2010, 2014 och 2018, och tittar på opinionsutvecklingen för varje parti från årsskiftet fram till valet respektive valår.
Och då blir ju frågan - hur visar man detta grafiskt på bästa sätt? Det handlar om tidsseriedata, därmed blir standardvalet ett linjediagram. Inga konstigheter. Åtta partier, tre valår. In med alltsammans i ett linjediagram med de etablerade partifärgerna för att särskilja utvecklingen.
Opinionsstöd per parti fram till valet, år 2010, 2014 & 2018

Aj, mina ögon! Det här blev inte vackert. Den som kan dra några vettiga slutsatser av det här vinner en årsprenumeration på Qvintensen. Vad vi har landat i här, är vad som ibland brukar benämnas Spaghettidiagram. Det är helt enkelt linjediagram med ett flertal linjer som korsar varandra i sån utsträckning att det inte går att göra någon egentlig analys. Tyvärr är det här vanligare än vad man kan tro. Det är också en av linjediagrammens svagheter; det är alldeles för lätt att dränka dem i närliggande datapunkter så att man inte ser skogen för alla träd.
Det finns några olika strategier för att åtgärda det här, men jag ska fokusera på en av dem. Nämligen att separera linjerna till flera parallella diagram. Men här gäller det att hålla tungan rätt i mun och tänka efter enligt vilka dimensioner man ska separera efter. Vi har dels parti, dels valår. Börjar vi lite försiktigt och delar upp efter år får vi visserligen rätt eleganta, rena tidsserier per valår.
Opinionsstöd per år fram till valet, 2010, 2014 & 2018


Men det här blev ju inte så roligt. Det här är samma typ av diagram man ser nästan dagligen under valspurtens sista skälvande dagar. Varje partis utveckling jämfört med de andra partierna. Det blir ganska svårt att dra några generella slutsatser om hur varje parti historiskt har klarat valspurterna, och vilka likheterna eller skillnaderna är mellan åren. Nej, att dra isär diagrammen efter år blev inte så bra.
Då testar vi att titta på ett parti i taget istället, med utvecklingen under respektive valår. Genast blir det mycket mer intressant.
Opinionsstöd per parti, fram till valet år 2010, 2014 & 2018



I första hand är det förstås själva diagramhantverket jag koncentrerar mig på i den här bloggen, men det finns åtskilliga intressanta iakttagelser här, rent innehållsmässigt. Tittar vi på moderaterna, så ser vi att de tidigare år haft varierande utveckling fram till valet, men i år verkar de ha plockat endast det sämsta från tidigare valrörelser. Det har varit en lika stor nedgång från årsskiftet fram till juni som det var 2014, men en fortsatt lika stor nedgång från juni fram till valet som det var 2010. Inget bra valår för dem.
Socialdemokraterna verkar däremot åtminstone vara konsekventa i sina misslyckade valår, fast i år ligger de på en ännu lägre nivå. 2010 och 2014 är faktiskt i det närmaste identiska vad gäller opinionens utveckling.
Miljöpartiet har tidigare år inte gjort särskilt bra valspurtar, men i år har de skärpt till sig. Från att ha legat och pendlat farligt nära fyraprocentsspärren har de nu stadigt ökat i opinionen, i rakt kontrast mot vad de gjorde både 2010 och 2014. Här ser man också ganska tydligt att deras uppgång faktiskt inleddes under april, redan innan superdödsmördarvärmen från Ryssland/Afrika/helvetet drog in över sommarsverige. Så det var nog inte bara hastigt uppflammande klimatångest som räddade partiet.
Men den största sensationen är utan tvekan kristdemokraterna. De brukar göra bra valspurtar och med nödrop klara sig över riksdagsspärren, men i år är utvecklingen helt sensationell. Från att ha dansat en veritabel dödsdans större delen av året, har de plötsligt nästan fördubblat väljarstödet och ligger nu över nivån från både 2010 och 2014. Det är svårt att se det som något annat än en partiledareffekt.
Och därmed har spaghettin kammats ut en aning. Det är som sagt aldrig fel att dela upp i många parallella diagram. Tydligheten ökar och förståelsen av data underlättas.
lördag 18 augusti 2018
Väljarna röstade på näst bästa parti - du kan inte ana vad som hände sen!!!
Jag fortsätter att gräva i SCB:s Partisympatiundersökning (PSU). Förutom frågan om vilket parti man skulle rösta på om det var val idag, finns även uppgifter om vilket man anser vara näst bästa parti. Med andra ord - om man inte skulle rösta på sitt förstahandsval, vilket parti skulle man kunna tänka sig att rösta på istället? Det här kan ge en bra indikation på vilken ytterligare potential det finns för varje parti att växa.
I det första diagrammet visas opinionsläget i PSU maj 2018. Dessutom adderas de ytterligare sympatier som andra väljare har i andra hand för respektive parti. Diagram med fördelning på politisk inriktning har fördelen av att det finns etablerade färger för respektive parti, vilket underlättar tolkningen. I normala fall skulle man inte skilja staplarna åt med olika färger, eftersom du redan har en förklaring i axeletiketterna. Särskiljande färger tillför ingen ytterligare information och bör därför elimineras. Men i det här fallet bidrar som sagt de etablerade och välkända färgerna till tolkningen.
Vän av ordning (eller i alla fall vän av diagram) ser dock omedelbart ett tolkningsproblem med diagrammet. Staplarna för den grundläggande opinionsnivån summeras naturligtvis till hundra, eftersom det handlar om hur hela opinionsnivån fördelas på de olika partierna. Den ytterligare potentialen däremot innebär att summan av samtliga staplar blir betydligt större än hundra procent (vissa väljare uppger inget näst bästa parti, så potentialen uppgår inte riktigt till ytterligare etthundra procent). För att ett visst parti ska uppnå sin fulla potential, måste dessa röster komma från andra partier. Diagrammet kan därför inte tolkas som att alla partier samtidigt kan växa, utan måste tolkas separat utifrån respektive parti. Knepigt, men inte omöjligt.
Opinionsläge PSU maj 2018 om det var val idag, samt ytterligare röster vid val av näst bästa parti

Sett till själva innehållet, så framgår det att totalt sett är främst Moderaterna och Centern som flest uppger som näst bästa parti. Relativt sett är det främst Liberalerna som skulle ha mest att vinna på att andra partiers väljare skulle rösta på sitt näst bästa parti, då man skulle mer än fördubbla stödet.
Men som sagt så kan inte alla partier ta hem röster för näst bästa parti samtidigt. Väljaropinionen är fortfarande ett nollsummespel. Det lite mer intressanta blir då istället att se - parti för parti - varifrån de "näst bästa" rösterna kommer ifrån. Och då i synnerhet i ett blockperspektiv. Kan partierna räkna med att ta hem röster från andra politiska block, eller handlar det främst om att kannibalisera den egna sidan?
Vi tittar därför istället på en uppsättning diagram där utgångspunkten är att ett parti i taget har hämtat hem alla "näst bästa" röster från övriga partier. Vad innebär det för de politiska blocken? Staplarna i blockdiagrammen med de ljusare färgtonerna representerar det ursprungliga opinionsläget enligt PSU maj 2018, medan de mörkare visar på resultatet om respektive parti även får "näst bästa" rösterna från de övriga.
Opinionsläge PSU maj 2018 per parti, ytterligare röster vid val av näst bästa parti samt förändring av stödet per block vid val av näst bästa parti


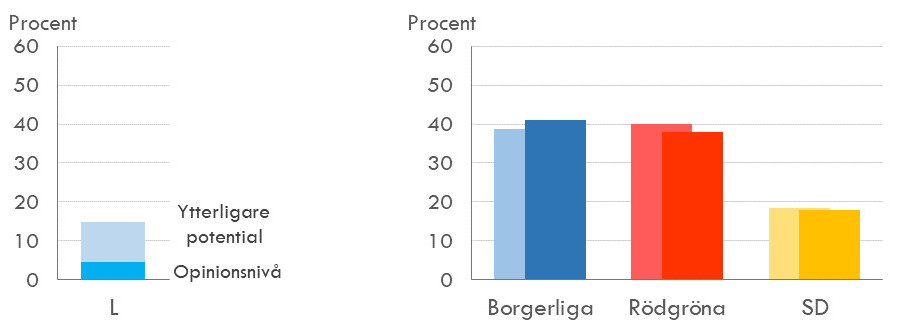





Det allra mest intressanta resultatet gäller Moderaterna. Med fullt utnyttjande av sin potential skulle man kunna uppnå omkring 40 procent i opinionen. Men huvuddelen skulle inte komma från andra borgerliga partier, utan till största delen från Sverigedemokraterna. Flödet fram och tillbaka mellan de båda partierna har varit avsevärt och just nu utgörs de sverigedemokratiska väljarna till stor del av tidigare moderatväljare som kan tänka sig att återgå till det partiet som ett andrahandsval. Ett växande Moderaterna skulle med andra ord påverka blockfördelningen i stor utsträckning, där Alliansen skulle få ett stöd på strax över 50 procent, medan de rödgröna skulle minska till ca 36 procent och SD till ca 10.
Tittar vi däremot på vad det skulle innebära om Sverigedemokraterna kunde tillgodoräkna sig alla "näst bästa" röster, så har de inte lika stor potential att växa. Rösterna hämtas i viss mån från de rödgröna, men i något större utsträckning från Alliansen. Sammantaget så har redan väldigt många som kan tänka sig att rösta på Sverigedemokraterna redan gjort slag i saken.
För Alliansen i övrigt så skulle vare sig Centern eller Liberalerna hämta några röster från Sverigedemokraterna. Ytterligare röster på Liberalerna skulle främst tas från andra borgerliga partier, vilket skulle göra att blockfördelningen bara skulle påverkas i mindre utsträckning. Centern har däremot en stor del av sina potentiella väljare hos det rödgröna blocket, vilket skulle minska i större utsträckning än om Liberalerna skulle växa.
Socialdemokraterna skulle också ha en del potentiella väljare hos det motsatta blocket, men i ganska begränsad del hos Sverigedemokraterna. Ett intressant specialfall är däremot Vänsterpartiet. Man har en tillväxtpotential på ytterligare nästan tio procent av opinionen, men skulle man hämta hem alla de rösterna skulle de rödgröna totalt sett endast växa med knappt två procent. Nästan alla röster skulle tas från Socialdemokraterna eller Miljöpartiet.
Förutsatt att väljarna faktiskt är beredda att byta parti till näst bästa, så skulle faktiskt det parlamentariska läget kunna förändras en hel del. Men den största potentialen till förändring handlar om att Moderaterna kan hämta tillbaka Sverigedemokratiska röster. Socialdemokraterna har också möjligheter genom att ta röster från både Sverigedemokrater och Alliansen, men faktiskt inte i lika stor utsträckning.
lördag 11 augusti 2018
SD:s väljare kommer och går
Valet närmar sig och med det mängder av statistik på längden
och tvären. Dags att damma av bloggen igen och dyka ner i siffrorna.
Den enskilt största förändringen i det politiska landskapet
är så klart Sverigedemokraternas tillväxt i opinionen. Vi står inför ett helt
nytt parlamentariskt läge, med tre snarare än två politiska block. För att
kunna gå från ingenting till ett tjugoprocentsparti, så måste så klart väljarna
komma någonstans ifrån. Därför tänkte jag titta lite närmare på hur
väljarströmmarna har gått mellan partierna, med fokus på just Sverigedemokraterna.
Inga politiska synpunkter i övrigt.
Det bästa och mest lättillgängliga dataunderlaget är SCB:s Partisympatiundersökning (PSU). Här finns skattningar dels – så klart – av opinionsläget
(partival om det varit val idag) för maj och november varje år, dels vilket
parti respondenten uppgav i förra PSU:n. Det ger alltså en bra möjlighet till
att följa hur väljare byter mellan olika partier och därigenom att se varifrån
väljare hos växande partier kommer.Tittar vi på opinionsläget för Sverigedemokraterna från 2011 till senaste PSU maj 2018, har de gått från drygt fem procent av opinionen till nästan tjugo, med en topp i novembermätningen 2015. Utvecklingen illustreras så klart bäst med ett vanligt linjediagram, eftersom fokus är förändringen över tid.
Andel som väljer Sverigedemokraterna om det var val idag enligt PSU, 2011-2018. Källa: SCB
{kind=link}

Omkring femton procent av väljaropinionen har alltså kommit
från andra partier under en period av sju år. Som situationen är, så handlar
det i allt väsentligt om Moderaterna och Socialdemokraterna. Sett ur det här
perspektivet är de övriga partierna att betrakta som brus. Inledningsvis tittar
vi därför på hur nettoflödet mellan S och SD respektive M och SD ser ut för
varje halvårsperiod som PSU mäter. S och M kan alltså antingen växa eller
krympa på SD:s bekostnad under respektive period.
Här är det snarare nivåskattningarna som är det viktiga, så
stapeldiagram blir mer relevanta än linjediagram. En annan viktig aspekt är
också ifall det är fråga om en nettoökning eller en nettominskning. Det framgår
visserligen av huruvida stapeln är över eller under skalans nollnivå, men det
finns anledning att underlätta tolkningen av visualiseringen genom att variera
färgerna med en justering av färgintensitet. Diagram med fokus på politiska
partier har fördelen av att det redan finns etablerade färger som sällan kräver
ytterligare förklaring. Här väljer jag att helt enkelt ha en något ljusare
färgton för nettominskningar.
Att försöka lägga in staplarna i samma diagram som
linjediagrammet över SD:s utveckling är inte en aktuellt. Det är generellt sett
alltid sämre att lägga in två olika skalor i samma diagram, eller att blanda
diagramtyper. Nej, vi håller nettoflödena separat från nivåskattningen.
Dessutom väljer jag att separera S och M i olika diagram. Det hade varit
möjligt att lägga in dem i samma, eftersom vi ändå skiljer dem åt med färger,
men min bedömning är att det skulle bli rörigare och svårare att särskilja de
olika partierna åt. Försök undvika att belamra diagrammen om möjligt. Jag har dock
gjort ett tillägg, med hjälptexter för att förtydliga tolkningen av vad som är
nettoökning och vad som är nettominskning gentemot SD.
Nettoförändring (procentenheter av opinionsstödet) för Moderaterna gentemot Sverigedemokraterna, enligt PSU 2011-2018 (Källa: SCB)

Nettoförändring (procentenheter av opinionsstödet) för Socialdemokraterna gentemot Sverigedemokraterna, enligt PSU 2011-2018 (Källa: SCB)

Själva innehållet då? SD:s tillväxt tog fart ordentligt från
2014. Innan dess är det svårt att se några tydliga trender. Rörelserna till och
från Moderaterna var små men mestadels till M:s nackdel, medan det växlade
kraftigt fram och tillbaka mellan S och SD. En ökning av S på SD:s bekostnad
ena perioden tog tillbaka igen perioden efter. Från 2014 blir trenden däremot mer
uppenbar – i allt större utsträckning är det moderata väljare som går till SD,
medan tappet från S ligger på en ganska konstant nivå. Under 2016 och senare
delen av 2017, när SD börjar backa i opinionen, tar M ganska snabbt tillbaka en
stor andel av väljarna. Återgången till S är däremot klart begränsad. Men det
är tydligt att vi har att göra med en väljargrupp som är snabb att gå fram och
tillbaka mellan M och SD, medan rörligheten till och från S över tid har
avtagit.
Tilläggas ska också att motsvarande diagram hade kunnat
göras för övriga partier, men rörelserna är så små att de mestadels faller inom
felmarginalen. Summeras nettoförändringen gentemot SD för alla partier förutom
S och M, uppgår de ändå bara till en fjärdedel av den totala rörligheten.
Men det finns (minst) en ytterligare aspekt av det här.
Bakom varje nettoförändring ligger bruttoförändringar. Även om ett parti
krymper på SD:s bekostnad totalt sett, så är det flöden både till och från partiet
under samma period, vars slutsumma utgör nettoresultatet. Det blir snabbt
mycket data, så skulle man försöka visa samtliga flöden till och från SD för
alla mätperioder skulle det bli svåröverskådligt, även om det så klart finns
tekniker för även det. Istället väljer jag att plocka ut två separata perioder;
en där SD vuxit och en där de backat, för att se skillnaderna mellan
väljarflödena.
Som oftast är det egentligen stapeldiagram som passar bäst
för nivåjämförelser, men här stöter vi på något som inte är helt ovanligt – det
s.k. ”mountains and molehills”-problemet, dvs. att det är stora skillnader i
skala mellan olika kategorier som jämförs. Man tvingas anpassa diagrammets
skala efter det största värdet, och är det andra kategorier med jämförelsevis
små värden, så krymper de så att man har svårt att urskilja skillnaderna mellan
dem. I det här fallet handlar det om att illustrera att SD:s väljare i absolut
störst utsträckning även valde SD förra perioden, men att det även finns
väljare från andra partier föregående period, men i betydlig mindre
utsträckning. Du skulle få ett diagram med en hög stapel och ett antal
svårurskiljbart små.
Det finns egentligen inga bra lösningar på det här
problemet, bara mer eller mindre dåliga. Jag har här valt ett alternativ med
bubbeldiagram. Här är det ytan som visual
cue, vilket (i enlighet med tidigare blogginlägg) egentligen är ett klart
sämre alternativ än staplar. Men det är tillåtet att bryta mot reglerna om man
vet vad man gör och varför – vilket jag gör. Här är det inte de exakta nivåerna
som det relevanta. Vi har redan tagit höjd för utgångspunkten i de föregående
diagrammen. Istället handlar det om att rangordna övriga partier och ge en
ungefärlig uppfattning av storleksnivåerna. Till det duger bubbeldiagrammen
gott.
Mer specifikt tittar vi på SD:s uppgång mellan maj och
november 2015 och deras tillbakagång mellan maj och november 2017, för att se
både hur väljarflödena går till och från övriga partier i båda fallen.
Andel som väljer Sverigedemokraterna om det var val idag enligt PSU, 2011-2018. Källa: SCB

Själva flödena visualiseras med bubbeldiagram för start- och
sluttidpunkt, med pilar för att underlätta tolkningen av flödet.
Bruttoförändring av opinionsstöd enligt PSU för Sverigedemokraterna till och från övriga partier maj-november 2015

Bruttoförändring av opinionsstöd enligt PSU för Sverigedemokraterna till och från övriga partier maj-november 2017

Det viktigaste budskapet i diagrammet är förstås att visa
att det ligger bruttoflöden bakom alla nettoflöden. Dvs. även när ett parti
växer så är det samtidigt väljare som går ifrån det till andra partier. På
samma sätt som är det väljare som går över till SD även om det totalt sett
backar i opinionen.
Vi ser här också några intressanta skillnader mellan SD:s
tillväxt och tillbakagång. Totalt sett så är det fler väljare som går från
partiet trots att det växer totalt sett vid uppgång, än vad det är som går till
det från andra partier vid tillbakagången. KD:s roll är också intressant; under
2017, när SD backar, är det fler som går till SD från KD än vad det går från S
till SD. Det är även markant att inga tidigare SD-väljare går till C vid
partiets nedgång. Perioden sammanfaller med Centerpartiets tillbakagång.
Samma typ av analys kan så klart göras för alla andra
partier, men i dagens opinionsläge känns det ändå mest intressant att titta närmare
på SD. PSU är en guldgruva för att göra analyser av det politiska läget, och
jag återkommer till andra aspekter av det i kommande blogginlägg.
måndag 23 januari 2017
”Jag tyar nog lite mer, Karl-Oskar”
En fråga som jag stötte på i facebookflödet i samband med
att Sveriges befolkning är på väg att passera tio miljoner, gällde vad som hade
hänt om den stora emigrationen till Amerika aldrig hade ägt rum. Nästan 1,2
miljoner svenskar flyttade till Amerika mellan 1850 och 1940. Vissa av dem
flyttade så småningom hem igen, men de flesta blev kvar, vilket innebar ett
permanent bortfall i Sveriges befolkning. I och med senaste presidentvalet
kanske det även finns skäl att anta att så många svenskar inte heller är så
intresserade av att emigrera idag.
Kan man räkna på vad som skulle ha hänt om emigrationen
aldrig inträffat? Det skulle bli ett
slags kontrafaktiskt scenario, eller alternativ historieskrivning. Med hjälp av
SCB:s föredömligt långa tidsserier för befolkningsutveckling är det lätt att ta
fram utvecklingen över total in- och utvandring år för år. En ganska
lätthanterlig sammanställning över vilka länder det rör sig om går också att
plocka ut.
Jag gör antagandet att inga svenskar flyttade till
Nordamerika (USA och Kanada) under perioden 1850 till 1940 och tar helt enkelt
bort dem ur från antalet utflyttade. Dock var det även en del som flyttade
tillbaka, så jag antar också att all invandring från USA och Kanada denna
period var återvändare, och plockar bort dem också. Vi får alltså ett nytt och
större (eller mindre negativt) flyttnetto för dessa år. Men vi måste även räkna
om födelsenettot – större befolkning ger upphov till fler barn. Jag gör här en
förenkling och räknar på födelsenetto som andel av total befolkning per år
under hela perioden, och använder den kvoten på den större befolkningen (genom
minskad utflyttning) för att få ett nytt födelsenetto respektive år ända fram
till idag.
Vad får vi då för resultat? Ett enkelt linjediagram passar
bäst för en så här lång tidsserie. Inga konstigheter – tydligt avskilda linjer
gör att de inte behöver särskiljas med färg och etiketterna sätts lämpligast
vid linjernas slut. Eftersom det också kan vara viktigt att läsa av linjernas
slutpunkter, är det också lämpligt att ha stödlinjer.
Befolkning i Sverige 1850-2015 med och utan
Amerikaemigration

Enligt mina grova beräkningar tycks det som att befolkningen
skulle varit drygt 11,6 miljoner år 2015, istället för 9,8 miljoner. En
skillnad på nära 1,8 miljoner invånare. I vårt kontrafaktiska scenario skulle
vi passerat tiomiljonerstrecket redan 1981, istället för 2017 som det blev i
verkligheten. Vi hade varit fler – men hade vi haft det bättre ställt?
Sannolikt inte. Det fanns goda skäl till att så många sökte lyckan på andra
sidan Atlanten. Skulle man på något sätt tvingat emigranterna att stanna hade
kanske fattigdom, svält och armod varit mycket mera utbredd, under mycket
längre tid.
Prenumerera på:
Inlägg (Atom)